Spark shell word count
Introduction
Nowadays, people are talking big data. But how to implement a big data application? There are an increasing number of framework emerging for manipulating large datasets. When it comes to big data framework, the first comes to one's mind must be Hadoop and Spark. Further discussion about the other framework may be found at the aritcle Top Big Data Processing Frameworks. Today I'm going to demonstrate a easy use of Spark shell solving word count problem.
Prereqisite
- Spark installation & environment (Spark overview)
- Word count text file (http://www.gutenberg.org/files/4300/4300.zip)
- Hadoop file system (optional)
Hadoop file system
Check the text file in the hadoop file system.
user@host:~$ hdfs dfs -ls /wordcount
Found 2 items
-rw-r--r-- 3 user group 556971991 2016-06-09 04:04 /wordcount/test.medium
-rw-r--r-- 3 user group 140 2016-06-08 03:21 /wordcount/test.smallSpark shell
Start the spark shell by the command spark-shell. If the environment hasn't been set, please see the Spark environment variables.
user@host:~/directory/wordcount$ spark-shell
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.1
/_/
Using Scala version 2.10.4 (OpenJDK 64-Bit Server VM, Java 1.7.0_91)Word count
First, use SparkContext object which represents a connection to a Spark cluster and can be used to create RDDs, accumulators, broadcast variables on that cluster to read a text in the HDFS (or local file system) and return it as a RDD of Strings.
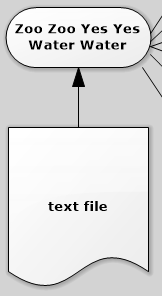
Second, transform the lines of String into a map of element splited by " ". If only a map function is used to split the RDD of Strings, a two layer map would be produced since the return of line of also seen as a delimiter. In this case, [[Zoo, Zoo, Yes], [Yes, Water, Water]].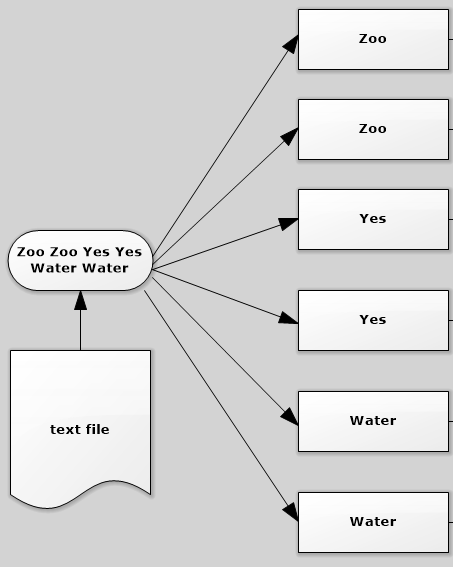
Third, map each element in the set to a map the indicate the element in the map have one occurance.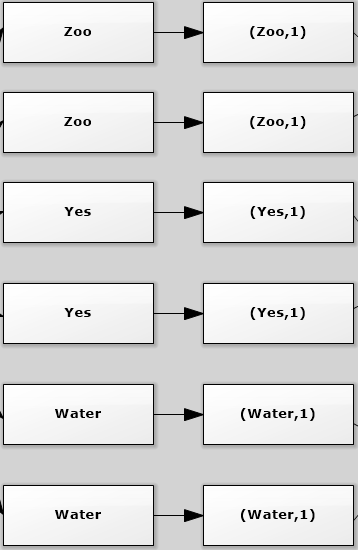
Fourth, reduce all the map elements by key and add the number of occurance in the map.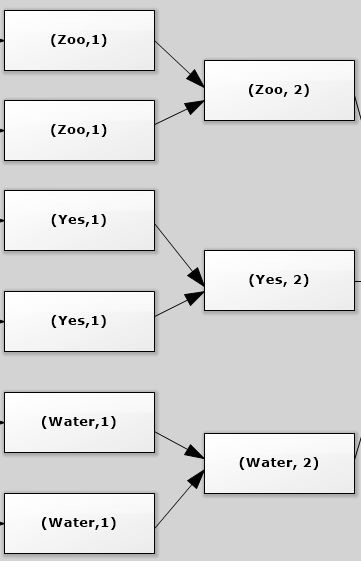
Finally, save the count of words to a text file.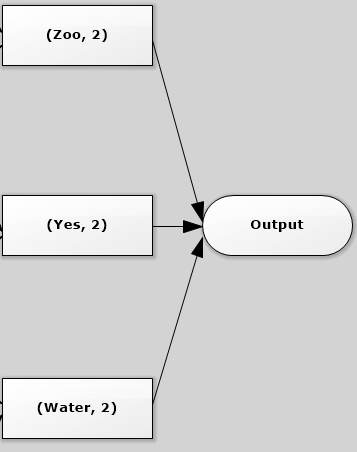

To see the output, use the HDFS command to list the file in the directory named word_count_output.
scala> var file = sc.textFile("hdfs://host:port/wordcount/test.medium")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:21Second, transform the lines of String into a map of element splited by " ". If only a map function is used to split the RDD of Strings, a two layer map would be produced since the return of line of also seen as a delimiter. In this case, [[Zoo, Zoo, Yes], [Yes, Water, Water]].
scala> var flat_map = file.flatMap(line => line.split(" "))
flat_map: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:23Third, map each element in the set to a map the indicate the element in the map have one occurance.
scala> var map = flat_map.map(word => (word, 1))
map: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:25Fourth, reduce all the map elements by key and add the number of occurance in the map.
scala> var count = map.reduceByKey(_ + _)
count: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:27Finally, save the count of words to a text file.
scala> count.saveAsTextFile("hdfs://host:port/user/user/word_count_output/")To see the output, use the HDFS command to list the file in the directory named word_count_output.
user@host:~/scala-example/wordcount/src/main/scala$ hdfs dfs -ls word_count_output/
Found 6 items
-rw-r--r-- 3 user user 0 2016-06-21 12:39 word_count_output/_SUCCESS
-rw-r--r-- 3 user user 198293 2016-06-21 12:39 word_count_output/part-00000
-rw-r--r-- 3 user user 191978 2016-06-21 12:39 word_count_output/part-00001
-rw-r--r-- 3 user user 197700 2016-06-21 12:39 word_count_output/part-00002
-rw-r--r-- 3 user user 199275 2016-06-21 12:39 word_count_output/part-00003
-rw-r--r-- 3 user user 196964 2016-06-21 12:39 word_count_output/part-00004user@host:~$ hdfs dfs -copyToLocal -p word_count_output(Darius,,124)
(virtuous,7405)
(unlawful,1163)
(woes,,1099)
(higher.,223)
(bound-,329)
(call?,459)
(neither-,92)
(preparations,,216)
(frightful,,128)
(Lamentable!,98)
(Sleep,1930)
(guards,781)
(Alas,1566)
(ordinaries,,104)
(thunder?,343)
(bowels,,338)
(print!",123)
(companion,1996)
(shin'st,119)
(fairer;,115)
(lisp,120)
(Meg,,309)
user@host:~/word_count_output$ cat part-00001Conclusion
At last, a full flow diagarm is shown below briefly. It's similar with the flow in the Hadoop word count example. But Spark is a in-memory clustering computing, so it's doesn't write the intermediate result to the disk. Also it approaches the problem using a lazy strategy, that is nothing would be executed unless you call some transformation or action that will trigger the job creation and execution (such as saveAsFile).