CUDA maximum value with parallel reduction
Introduction
Methods
// Device code
__global__ void VecMax(const float* A, float* B, int N)
{
extern __shared__ float cache[];
int i = blockDim.x * blockIdx.x + threadIdx.x;
int cacheIndex = threadIdx.x;
float temp = RAND_MIN; // register for each thread
while (i < N) {
if(A[i] > temp)
temp = A[i];
i += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp; // set the cache value
__syncthreads();
// perform parallel reduction, threadsPerBlock must be 2^m
int ib = blockDim.x / 2;
while (ib != 0) {
if(cacheIndex < ib && cache[cacheIndex + ib] > cache[cacheIndex])
cache[cacheIndex] = cache[cacheIndex + ib];
__syncthreads();
ib /= 2;
}
if(cacheIndex == 0)
B[blockIdx.x] = cache[0];
}// Allocates an array with random float entries in (-1, 1)
void RandomInit(float* data, int n)
{
for (int i = 0; i < n; ++i)
data[i] = rand() / (float)RAND_MAX * 2.0 + RAND_MIN;
}Tuning block and grid size
To reproduce the results, firstly run test_params.py. Wait for all jobs to complete. Lastly, run gather_results.py.
test_params.py
import os
import time
size_of_array = 40960000
testing_params = [(32, 4), (64, 4), (128, 4), (256, 4), (512, 4), (1024, 4),
(32, 16), (64, 16), (128, 16), (256, 16), (512, 16), (1024, 16),
(32, 32), (64, 32), (128, 32), (256, 32), (512, 32), (1024, 32),
(32, 64), (64, 64), (128, 64), (256, 64), (512, 64), (1024, 64), (32, 128), (64, 128),
(128, 128), (256, 128), (512, 128), (1024, 128)]
for params in testing_params:
in_name = '{}_{}_in'.format(params[0], params[1])
cmd_name = 'cmd_{}_{}'.format(params[0], params[1])
with open(in_name, 'wb') as f:
f.write('{}\n{}\n{}\n'.format(size_of_array, params[0], params[1]))
with open(cmd_name, 'wb') as f:
cmd_content = ('Universe=vanilla\nExecutable=/opt/bin/runjob\nMachine_count=1\n\n'
'Output=condor.out\nError=condor.err\nLog=condor.log\n\n'
'Requirements=(MTYPE=="TEST")\n\nRequest_cpus=1\n\n'
'Initialdir=/path/to/working/directory\n\nArguments=./vecMax {}_{}_in {}_{}_out\n\n'
'Queue\n\n').format(
params[0], params[1],
params[0], params[1])
f.write(cmd_content)
os.system('condor_submit {}'.format(cmd_name))
time.sleep(1)gather_results.py
import os
import subprocess
result_name = 'results.csv'
with open(result_name, 'wb') as f:
f.write('Size of the vector,'
'Number of threads per block,'
'Number of blocks per grid,'
'Input time for GPU,'
'Processing time for GPU (ms),'
'GPU Gflops,'
'Output time for GPU (ms),'
'Total time for GPU (ms),'
'Processing time for CPU (ms),'
'CPU Gflops,'
'Speed up of GPU,'
'|(h_G - h_C) / h_C|\n')
for file_name in os.listdir('./'):
if '_out' in file_name:
line = subprocess.check_output(['tail', '-1', file_name])
if not ',' in line:
continue
f.write(line + '\n')
f.close()Results
I have tested various parameter: number of threads per block, and number of blocks per grid. Here, some columns are omitted: size of the vector, GPU Gflops, and CPU Gflops.
The three parameter settings of the greatest speed up are highlighted in yellow. The processing time of them is actually only less than 1.5 milliseconds and the IO has occupy about 96% of the total time for GPU.
For those configuration having more threads and blocks, their speed ups have saturated to 1.6. I would investigate two specific configurations with one fixed and another varied.
The first case fixes the number of blocks per grid at 4 and varies the number of threads per block. When the number of threads per block is only 32, GPU performs worse than CPU. As the number of threads per block grows, GPU speed up also increases linearly.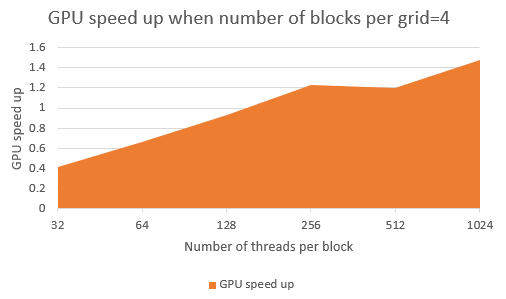
|
Number of threads per block |
Number of blocks per grid |
Input time for GPU |
Processing time for GPU (ms) |
Output time for GPU (ms) |
Total time for GPU (ms) |
Processing time for CPU (ms) |
Speed up of GPU |
|
32 |
32 |
30.66525 |
14.84906 |
6.784064 |
52.29837 |
63.9841 |
1.223443 |
|
64 |
32 |
30.64186 |
7.573888 |
6.781984 |
44.99773 |
64.16451 |
1.42595 |
|
128 |
32 |
30.65101 |
3.833824 |
6.780832 |
41.26566 |
63.9816 |
1.55048 |
|
256 |
32 |
30.6024 |
2.076 |
6.788832 |
39.46723 |
63.97824 |
1.621047 |
|
512 |
32 |
30.6233 |
1.39744 |
6.774432 |
38.79517 |
61.05914 |
1.573885 |
|
1024 |
32 |
30.6088 |
1.484768 |
6.780704 |
38.87428 |
64.14608 |
1.650091 |
|
32 |
64 |
30.61383 |
7.575488 |
6.783584 |
44.9729 |
64.15702 |
1.426571 |
|
64 |
64 |
30.62464 |
3.831616 |
6.781024 |
41.23728 |
64.1552 |
1.555757 |
|
128 |
64 |
30.58659 |
2.165824 |
6.77504 |
39.52745 |
61.06656 |
1.544915 |
|
256 |
64 |
30.50822 |
1.382816 |
6.77904 |
38.67008 |
61.05878 |
1.578967 |
|
512 |
64 |
29.3 |
1.453376 |
6.724992 |
37.47837 |
51.59056 |
1.376542 |
|
1024 |
64 |
28.83965 |
1.252736 |
6.71024 |
36.80262 |
51.53123 |
1.400205 |
|
32 |
128 |
30.5961 |
3.837504 |
6.784896 |
41.2185 |
63.97549 |
1.552106 |
|
64 |
128 |
30.6297 |
2.05072 |
6.782528 |
39.46294 |
63.9983 |
1.621732 |
|
128 |
128 |
30.60554 |
1.283488 |
6.781856 |
38.67088 |
63.97818 |
1.654428 |
|
256 |
128 |
30.64755 |
1.481664 |
6.779744 |
38.90896 |
64.01881 |
1.645349 |
|
512 |
128 |
30.60602 |
1.3216 |
6.774528 |
38.70215 |
61.05629 |
1.577595 |
|
1024 |
128 |
30.65517 |
1.184672 |
6.780032 |
38.61987 |
63.98534 |
1.656798 |
|
32 |
4 |
30.60259 |
118.0691 |
6.768384 |
155.44 |
64.28551 |
0.413571 |
|
64 |
4 |
30.59501 |
58.89587 |
6.769696 |
96.26057 |
63.87818 |
0.663596 |
|
128 |
4 |
30.58115 |
30.31491 |
6.772544 |
67.66861 |
62.76544 |
0.927541 |
|
256 |
4 |
30.64448 |
14.90966 |
6.780608 |
52.33476 |
64.23821 |
1.227448 |
|
512 |
4 |
28.80144 |
7.557408 |
6.710016 |
43.06886 |
51.52883 |
1.196429 |
|
1024 |
4 |
30.56736 |
4.092448 |
6.776416 |
41.43623 |
61.06 |
1.47359 |
|
32 |
16 |
30.57306 |
30.28375 |
6.77616 |
67.63296 |
62.59197 |
0.925466 |
|
64 |
16 |
30.62096 |
14.82234 |
6.782272 |
52.22557 |
64.01981 |
1.225833 |
|
128 |
16 |
30.6225 |
7.58512 |
6.781632 |
44.98925 |
63.98637 |
1.422259 |
|
256 |
16 |
30.65683 |
3.836832 |
6.78352 |
41.27718 |
64.03978 |
1.551457 |
|
512 |
16 |
30.61443 |
2.098848 |
6.782048 |
39.49533 |
63.97792 |
1.619886 |
|
1024 |
16 |
30.87216 |
1.3448 |
6.785248 |
39.00221 |
63.89149 |
1.63815 |
Conclusions
- The memory copying from host to device and from device to host is the dominant of the total time for GPU. Parallel reduction can help reduce the data transferring.
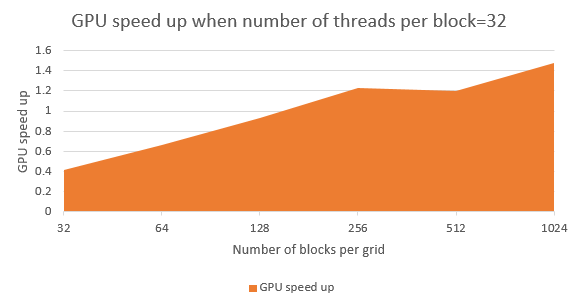
- When the number of blocks per grid is relatively small, it is better to increase the number of threads per block.
- When the number of threads per block is small, it is better to increase the number of blocks per grid.