Let's imagine a scenario that your company wants to download all the history and all the future data on the CWB Observation Data Inquire System. If we choose a manual approach, what steps we would go through? Possibly, open the options of cities and the options of stations and choose monthly data. Starting from August, 2013 to August, 2016, you would have to click through all the cities, all the stations, and all the data available. There are 126 stations and 37 months. If you are to use Excel to crawl the web page, there would be few steps to extract the important part of the web page.
First, copy the url for each station and each month.
Second, select the data tab and click on the from web button.
Third, paste the url into the address input.
Observing the data read from the web. There are some useless rows.
Select the important part and paste to the your workspace.
It's quite a hard work if we want to manually operate these steps. There is another way to acomplish the work. That is to write a web crawler.
Web page parameter
To crawl through all the history data in the CWB Observation Data Inquire System. We first have observe the url when the result of a query is shown. For example, http://e-service.cwb.gov.tw/HistoryDataQuery/MonthDataController.do?command=viewMain&station=466910&stname=%25E9%259E%258D%25E9%2583%25A8&datepicker=2013-08 tells that there are 4 parameters in this request.
command : viewMain
station : 466910
stname : %25E9%259E%258D%25E9%2583%25A8
datepicker : 2013-08
Observing the parameters above, it is obviously that the station and the date is what really matters in the query. But how could we obtain a list of the available stations?
Back to the web page for querying. We may see that the option for the stations is changed once the city option is altered. It's quite reasonable to infer that there must be a javascript code manipulating this form.
Look under the form. There is a script tag.
Copy the content in the stList and store in a file called keyfile.json.
varstList={"466880":["板橋 ","BANQIAO","新北市 "]...
Web crawler loop
# -*- coding: utf-8 -*-
importurllibtry:frombs4importBeautifulSoupexceptImportError:fromBeautifulSoupimportBeautifulSoupimportcsvimportchardetimportjson# variable for the crawling year.
year=2014# stations, station Chinese names, and cities.
stations=[]stnames=[]cities=[]# load the json file obtained from the web page.
withopen('keyfile.json')asdata_file:keyfile=json.load(data_file)# iterate through all the stations.
forkey,valueinkeyfile.items():stations.append(key)stnames.append(value[2])cities.append(value[0])# iterate through all the stations and month in a year.
foriinrange(0,len(stations)):formonthinrange(1,13):url='http://e-service.cwb.gov.tw/HistoryDataQuery/MonthDataController.do?command=viewMain&station='+str(stations[i])+'&stname=&datepicker=%4d-%02d'%(year,month,)printurldata=urllib.urlopen(url)# use soup library to parse the html. Note that the lxml parameter is optional.
soup=BeautifulSoup(data,"lxml")# select the table containing the data.
table=soup.find('table',{"id":"MyTable"})# Let the city, station number, and station name be the start of a row.
rows=[]start=[cities[i].encode('utf8'),stations[i],stnames[i].encode('utf8'),month]# Ignore the first two rows which is the header.
forrowintable.find_all('tr')[2:]:row_val=[val.text.replace(u'\xa0',u' ').encode('utf8')forvalinrow.find_all('td')]rows.append(start+row_val)# Append the result to a csv file
withopen('output_file.csv','ab')asf:writer=csv.writer(f)writer.writerows(rowforrowinrowsifrow)
Conclusion
To run the program, determine what year and what range of month you are interested in and change the value year and range. Type python (the file name) and the crawler would start iterate through the list of stations and the specified months.
The result csv may have to be read by the data tab from text button because of the encoding problem.
Then the annoying copy-and-paste task would be automatically completed by a web crawler! In fact, there are more subtle problem I didn't discuss in this article, such as the encoding of the Chinese words and the invisible space . The rest is leaved for your own discovery!
 Second, select the data tab and click on the from web button.
Second, select the data tab and click on the from web button.
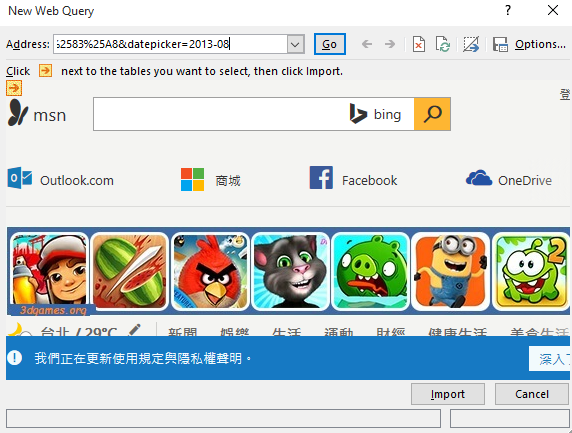
 Third, paste the url into the address input.
Third, paste the url into the address input.
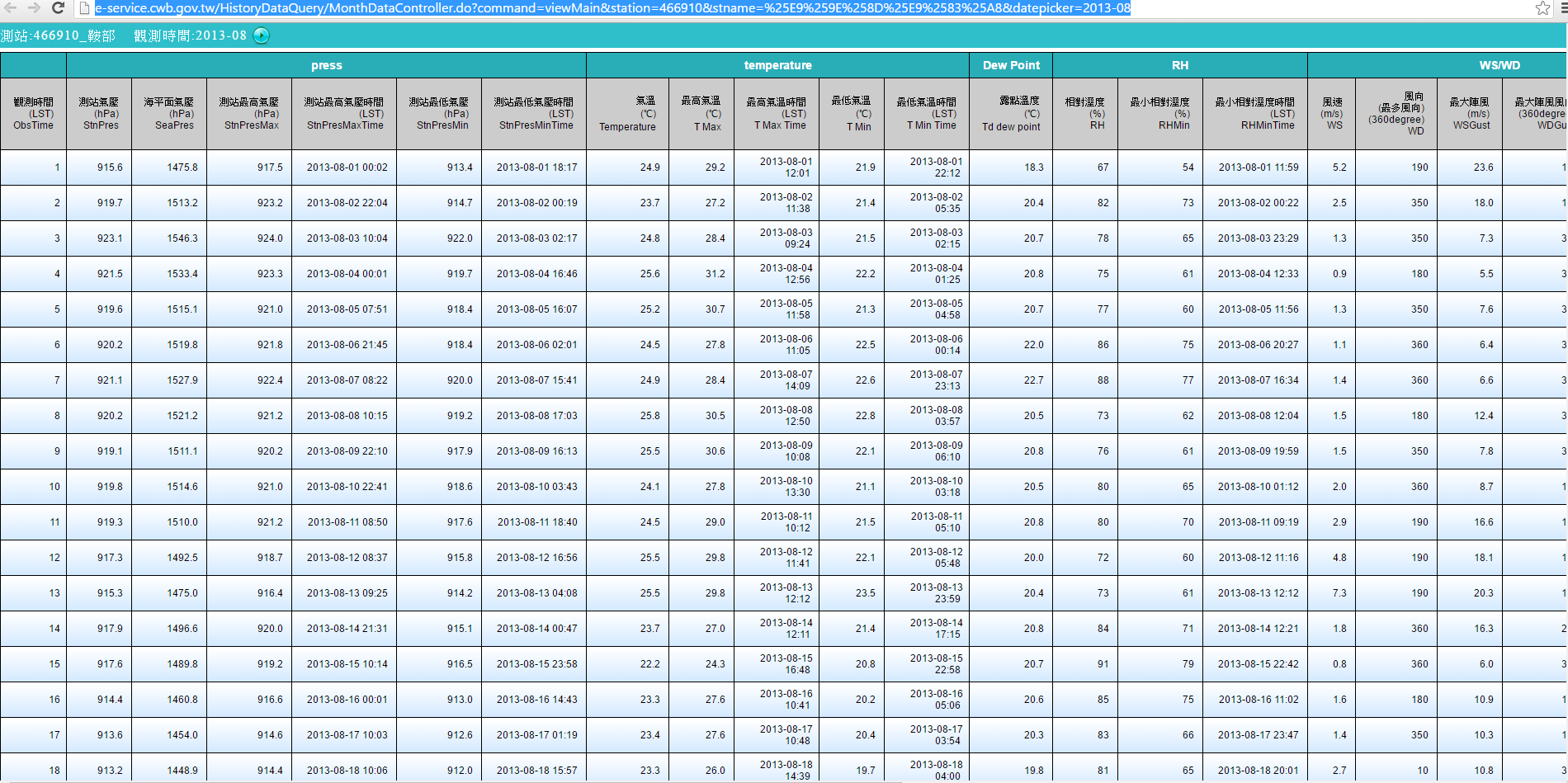
 Observing the data read from the web. There are some useless rows.
Observing the data read from the web. There are some useless rows.
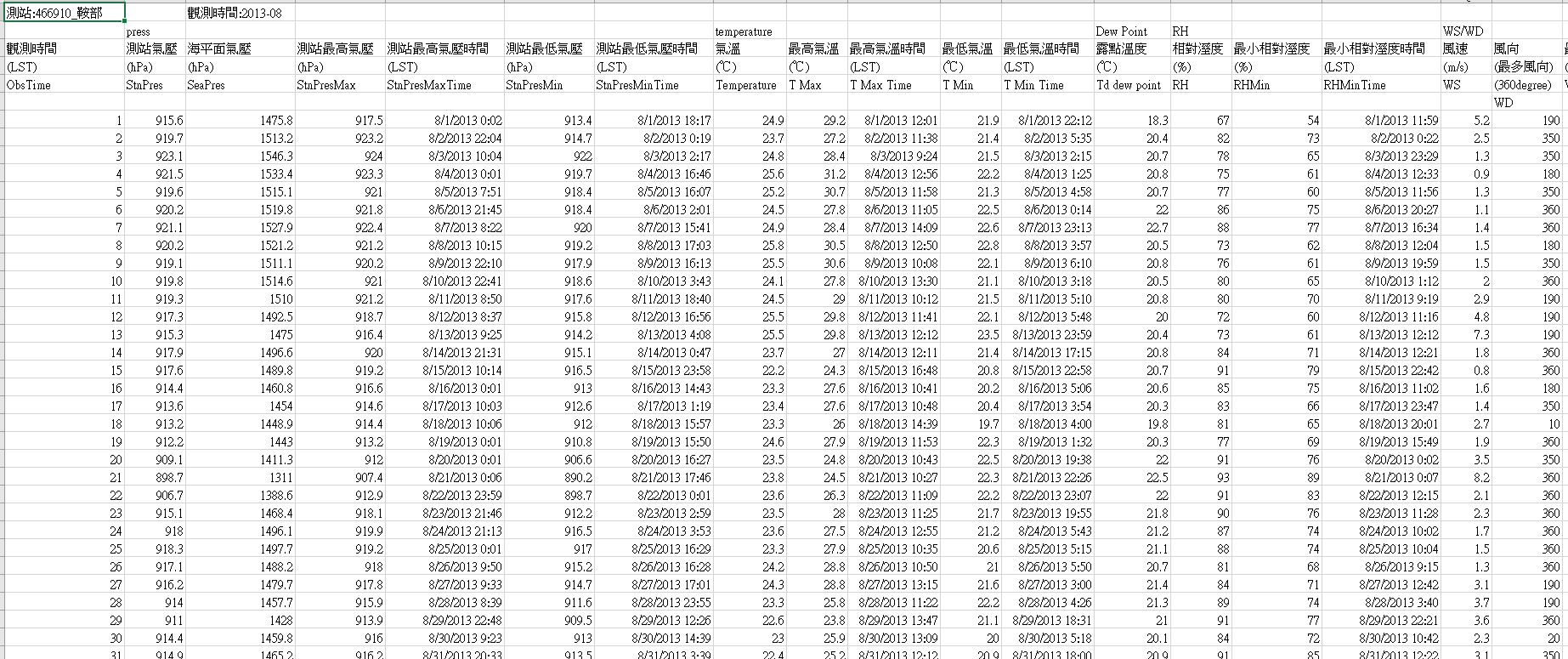 Select the important part and paste to the your workspace.
Select the important part and paste to the your workspace.
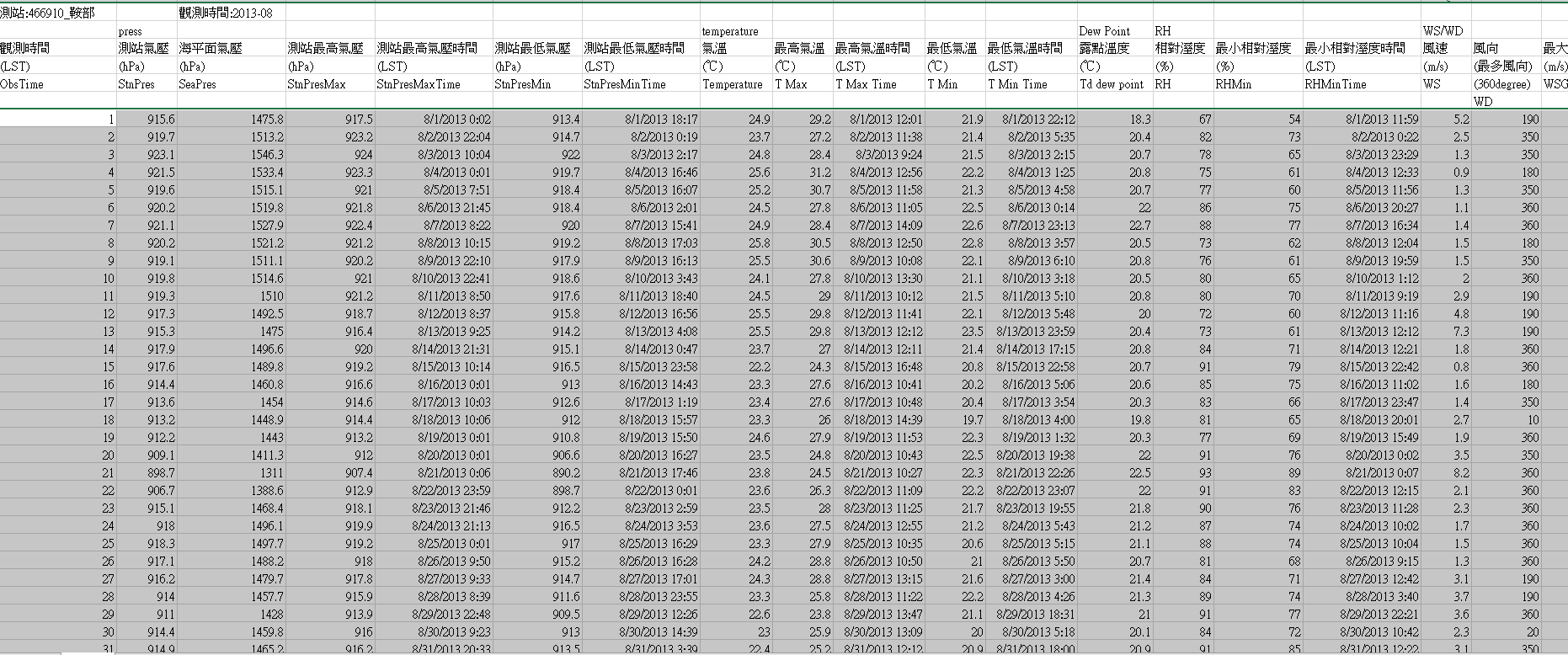 It's quite a hard work if we want to manually operate these steps. There is another way to acomplish the work. That is to write a web crawler.
It's quite a hard work if we want to manually operate these steps. There is another way to acomplish the work. That is to write a web crawler.
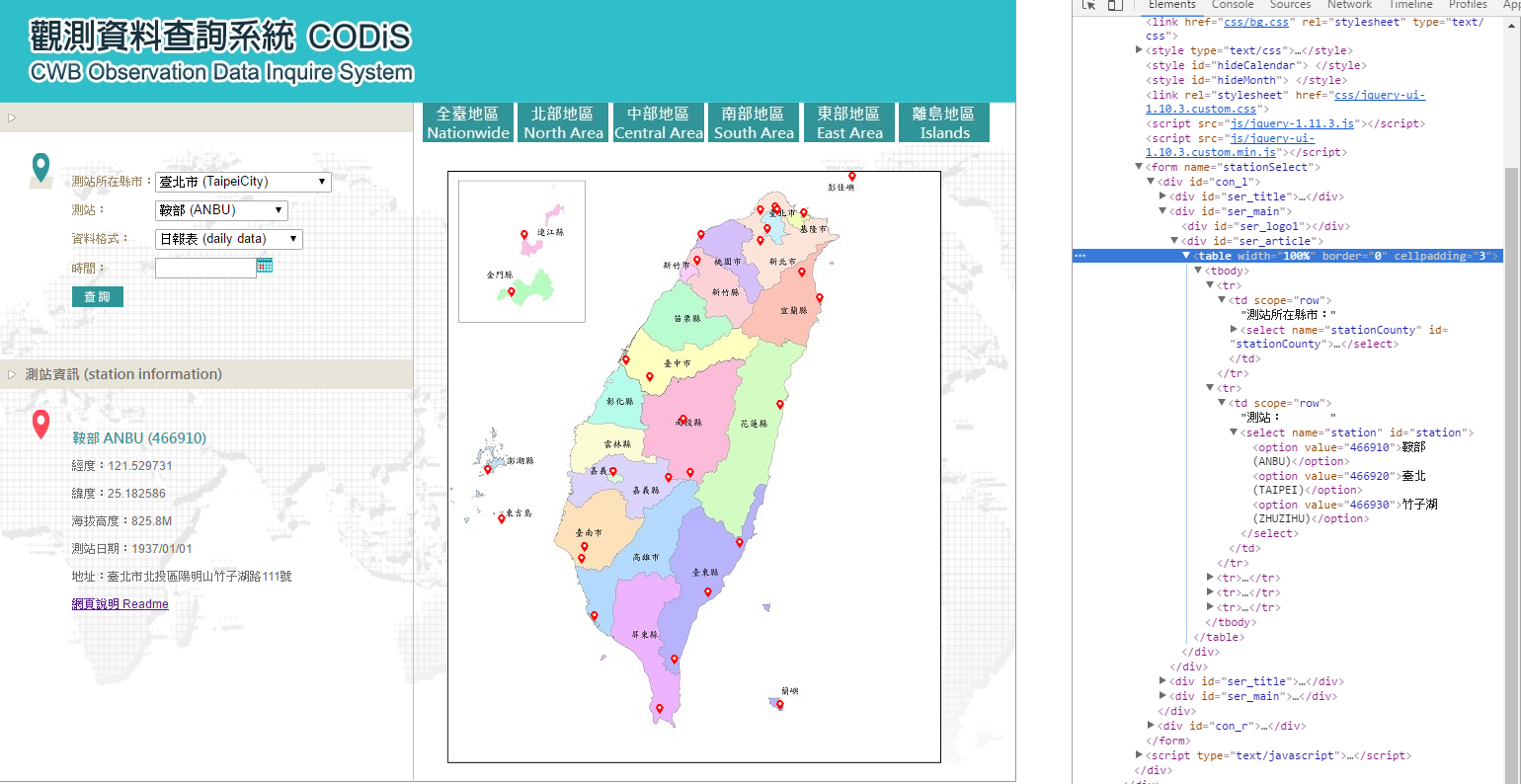 Look under the form. There is a script tag.
Look under the form. There is a script tag.
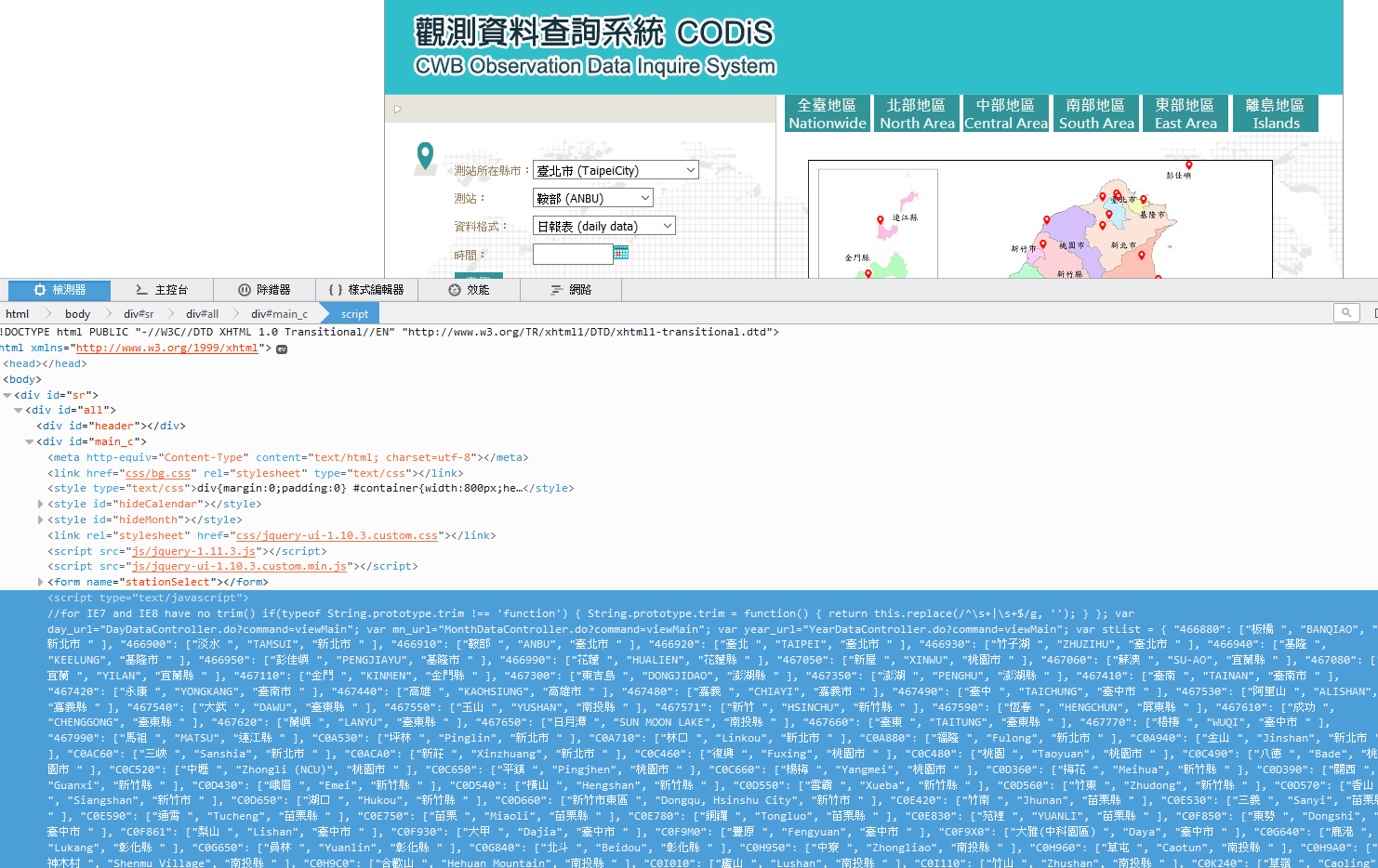 Copy the content in the stList and store in a file called keyfile.json.
Copy the content in the stList and store in a file called keyfile.json.
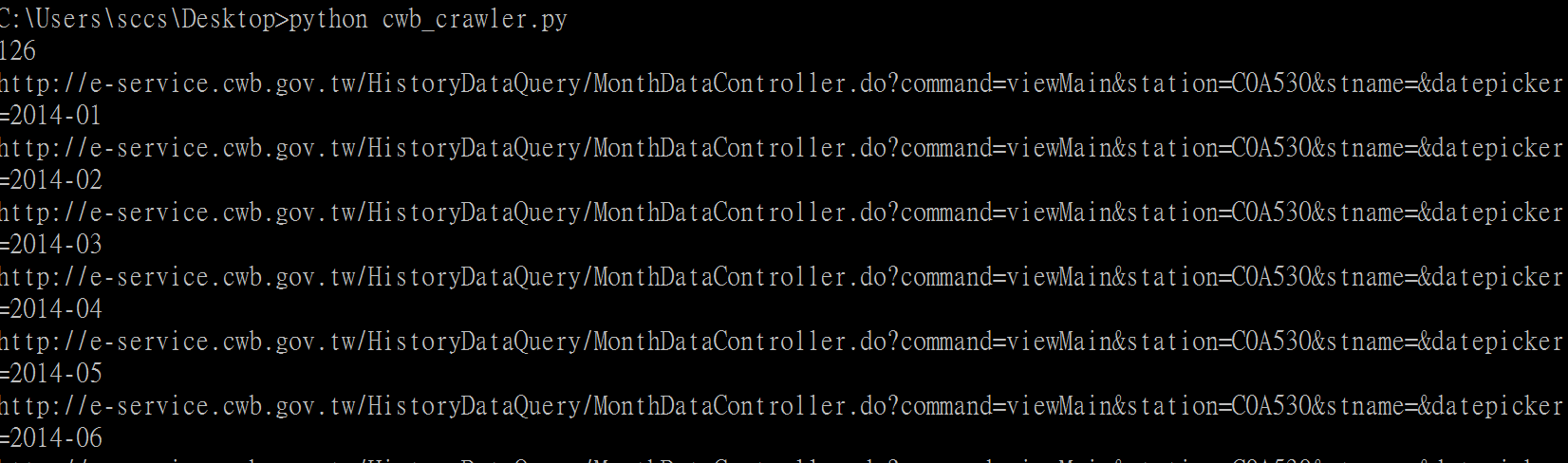 The result csv may have to be read by the data tab from text button because of the encoding problem.
The result csv may have to be read by the data tab from text button because of the encoding problem.
 Then the annoying copy-and-paste task would be automatically completed by a web crawler! In fact, there are more subtle problem I didn't discuss in this article, such as the encoding of the Chinese words and the invisible space . The rest is leaved for your own discovery!
Then the annoying copy-and-paste task would be automatically completed by a web crawler! In fact, there are more subtle problem I didn't discuss in this article, such as the encoding of the Chinese words and the invisible space . The rest is leaved for your own discovery!